Feb 12, 2026
Codex Helped Me Recover Lost Files in Minutes
I recently switched from Claude to Codex as my daily driver to see how things compare after months of using Claude Code. So far, Codex 5.3 has been surprisingly strong.
I’ve been building an action RPG in my spare time, and one of the tools I built with Claude was a mini CMS. The goal was simple: get a bird’s-eye view of all my game content in one place. The game has a lot of moving parts (enemies, encounters, encounter groups, materials, items, affixes), and while a TUI is excellent for fast batch edits, it’s not great for understanding overall game design and structure.
I scaffolded the CMS with shadcn’s create workflow:
bunx --bun shadcn@latest create --template vite
Note: The original command included a long preset URL (Radix/Nova/neutral variants), so I shortened it here for readability. You can generate your own preset command at ui.shadcn.com/create.
The Mistake
I missed something important during setup: this initialized a new Git repository inside my existing game repository. The CMS lived at Tools/content-editor, and Git treated it like a submodule, which meant parent-repo commits weren’t capturing the inner project the way I expected.
That turned into a real problem when I started cleaning up disk space. My 1TB M1 MacBook was filling up (mostly from Git LFS), so I wiped local history and reinitialized. Then I deleted my local folder, assuming everything important was already safely in Git.
It wasn’t.
Because of the submodule state, I effectively lost the CMS work (about five hours). I didn’t even notice until days later when I was on my PC and asked Codex to bring up the CMS. Its response was: “I’m confused: What CMS? I see a content-editor folder but it’s empty.”
Recovery
At that point, normal recovery options were rough: no reflog (folder gone), SSD recovery is painful, and rebuilding from scratch was going to be long and painful.
Then I remembered that Claude and Codex both keep detailed conversation history on disk. I also have an MCP tool I built called Clancey, which makes Claude conversation archives searchable. So I asked Codex to do a best-effort reconstruction from archived Claude sessions, using concrete file-write/edit history and ignoring older Next.js detours.
The transcript below is the actual sequence.
Transcript (Selected Excerpts)
I mistakenly initialized a Git submodule and failed to push my changes to the remote server. We lost all of our work.I believe there’s a way to get it back. We can rebuild it using Claude’s conversation archives. I have an MCP tool named Clancey that allows you to look through Claude Code conversations.
Can you make a best effort attempt to get it all back? This may take you a while, so strap in.
A couple of things to note:
- I initialized the repo using shadcn/ui create the last time I worked on this.
- I installed Zustand, TanStack Router, TanStack Query.
- I used a Vite proxy with a Hono backend.
- The Hono backend interacted directly with files on disk.
- If you see any Next.js code, ignore it. That was a previous version.
You can do this. Everything we did is in Claude Code. Is Clancey MCP working for you? That’s the first thing we need to verify.
Clancey is reachable and indexed on this machine, so we can use it for recovery. Next I’m pulling the most relevant archived conversations for Tools/content-editor and the stack details you listed.
clancey.search_conversations
I confirmed Clancey is working and found the exact conversation chain, including a pointer to the full archived transcript file. Next I’m inspecting the current Tools/content-editor directory state.
I found Tools/content-editor present with a full Node project and source files; next I’m diffing that against the archived conversation state.
Actually Tools/content-editor is a brand new repo from a Vite scaffold. Assume that everything is missing.
Understood. I’ll treat Tools/content-editor as fully lost and rebuild from conversation archives only. I’m extracting raw Claude transcript logs so we can recover file contents, not just summaries.
Read cd03f146-60d3-4d39-b575-5308c6668de5.jsonl
Search Write|Edit|MultiEdit|NotebookEdit in transcript JSONL files.
python3 - <<'PY'
...
106af70d-2f04-4c4a-a0a7-7a527bef2eeb.jsonl W:14 E:23 M:0 Files:24
4371e4e7-f918-4ee9-ad42-ff5716e5b322.jsonl W:1 E:3 M:0 Files:8
...
ced3940b-3265-412b-93dd-63834099e68b.jsonl W:1 E:2 M:0 Files:7
ecc2e447-3a8e-4a05-8ef9-ca520b839098.jsonl W:4 E:4 M:0 Files:28
PYCodex then proceeded to run a series of complex Python scripts which recovered my entire CMS almost perfectly. It missed a couple of more recent conversations, but all it took was asking Codex to search newer archives with Clancey and it just worked.
I was shocked. If I had done this by hand, it likely would have taken me hours, if not days.
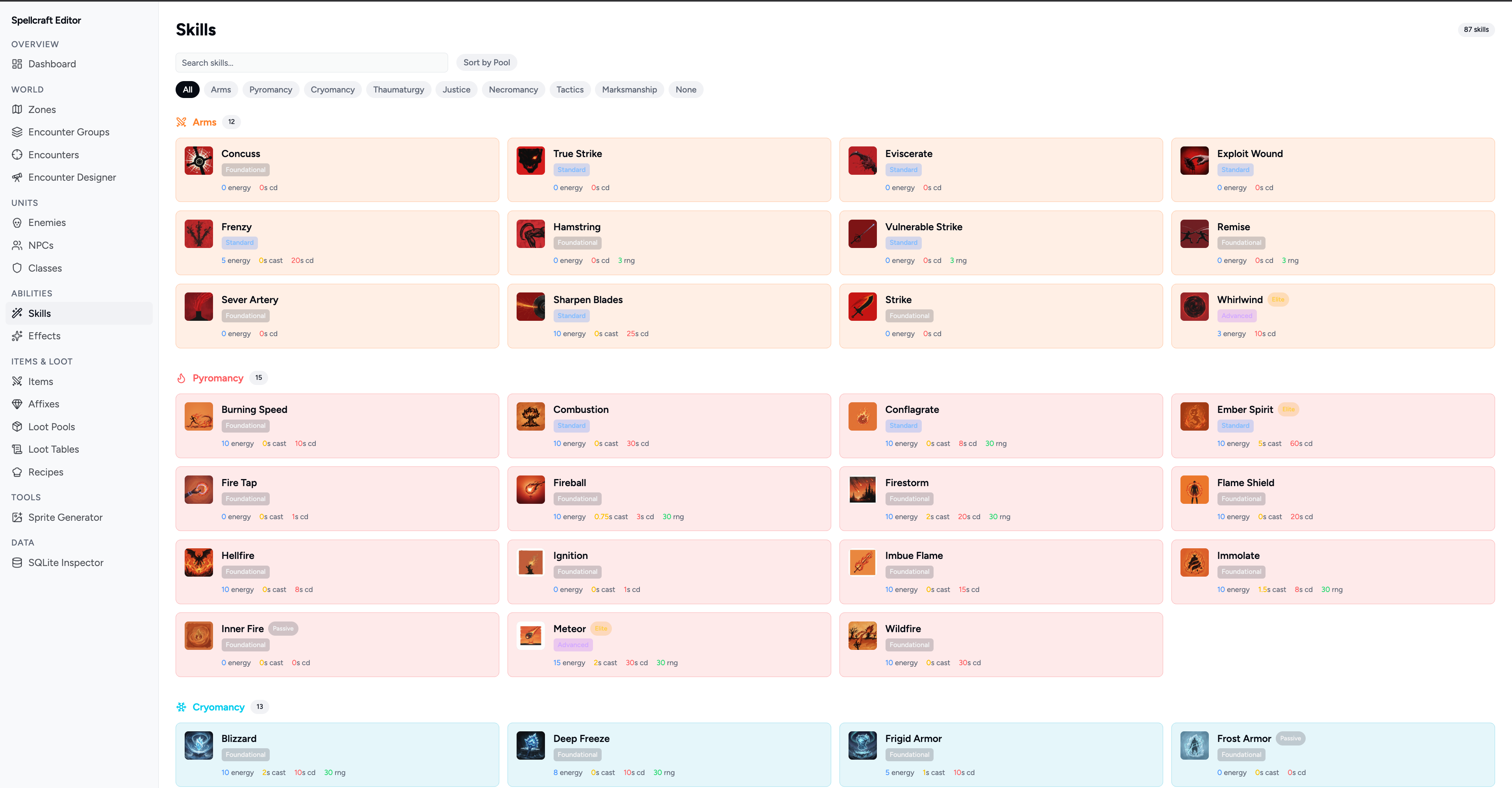
Tools/content-editor CMS after replaying archived edits.I’m Impressed
Codex helped me recover the entire CMS in a matter of minutes using a complex combination of Python and perl, something that would have normally taken me hours to do. It was so impressive I felt like writing a post about it.
I’ll continue to use Codex 5.3 as my daily driver for a bit and see how it goes. So far, my initial impressions are very positive.
How to avoid this in the future
These models are genuinely impressive. A year ago none of this was possible, and it’s easy to get used to how capable they are. I got too comfortable, stopped double-checking enough, and this mishap is entirely on me.
However, here are some rules I’ve set for myself for the future:
- Don’t use LLMs for scaffolding. They’re terrible at it, don’t work well with workflow-based scaffolding tools, and usually struggle with new technologies even after looking up documentation.
- Double check Git commands when they’re run by an LLM. I usually tell the LLM to “stage everything, commit and push” and the LLM will only stage certain things, or fail to notice that a submodule was not committed (this was the big blunder that I should have noticed).